SQL Server Intercalación
Introducción
Microsoft SQL Server, como
un sistema de administración de bases de datos, tiene entre sus propósitos la
entrega de los datos en un cierto orden, de esta manera utiliza lo que se
denomina intercalación que podemos describir como el proceso de cotejo y
ordenamiento.
Según el
diccionario, Cotejo se define como: el acto de reunir personas o elementos en
un orden para un propósito específico.
La intercalación
de Microsoft SQL Server se identifica con una sencilla cadena de caracteres para especificar el
nombre. Es importante indicar que Microsoft SQL Server soporta tanto el uso de intercalación de Windows como de Microsoft SQL
Server, existen alrededor de 80 nombres de intercalación que pueden ser usados
en Microsoft SQL Server y que fueron desarrolladas antes de que soportara las de Windows,
es por ello que las intercalaciones de Microsoft SQL Server aun se soportan como
compatibilidad de las versiones anteriores, Microsoft recomienda el uso de intercalación
Windows en lugar de la intercalación de Microsoft SQL Server en nuevas instalaciones y
desarrollos.
Página de código
Es importante
mantener en mente que para llevar a cabo la intercalación existe un elemento
denominado página de código, que en computación es una codificación de
caracteres, esto es, la asociación especifica de un conjunto de caracteres
imprimibles y caracteres de control con numeración única. El término "página
de código" fue introducido por IBM en los sistemas mainframe basados en
EBCDIC. La mayoría de los proveedores, como Microsoft, identifican sus propios
conjuntos de caracteres por un nombre. Originalmente, los números de página de códigos
se refieren a los números de página en el manual del juego de caracteres estándar
de IBM, una condición que no se ha mantenido durante mucho tiempo. Los
proveedores que usan un sistema de página de códigos asignan su propio número
de página de códigos a una codificación de caracteres, incluso si es mejor
conocido por otro nombre; por ejemplo, a UTF-8 se le han asignado el número de página
65001 en Microsoft.
Nombres de Intercalación
Intercalación de SQL
Los nombres de intercalación
que se pueden encontrar en el caso de los que se desarrollaron para Microsoft SQL Server
mantienen la siguiente sintaxis.
Nombre_Intercalación_SQL
= SQL_ReglasDeOrden[_Pref]_CPPáginaCódigo_EstiloComparación
Donde:
- ReglasDeOrden es una cadena que identifica el alfabeto o lenguaje cuyas reglas de clasificación se aplican cuando se especifica la clasificación del diccionario.
- Pref especifica la preferencia en mayúsculas. Incluso si la comparación no distingue entre mayúsculas y minúsculas, la versión en mayúscula de una letra se ordena antes que la versión en minúscula, cuando no hay otra distinción.
- PáginaCódigo Especifica un número de uno a cuatro dígitos que identifica la página de códigos utilizada por la clasificación. CP1 especifica la página de códigos 1252, para todas las demás páginas de códigos se especifica el número de página de códigos completo. Por ejemplo, CP1251 especifica la página de códigos 1251 y CP850 especifica la página de códigos 850.
- EstiloComparación es la combinación de estilos que identifican la sensibilidad de mayúsculas y minúsculas, indicando ya sea CI como insensible en mayúsculas y minúsculas o CS como sensible en mayúsculas y minúsculas; la sensibilidad de los acentos, indicando ya sea AI como insensible en acentos o AS como sensible en acentos; o bien se puede indicar el orden de clasificación binario.
Para enumerar las
intercalaciones de Microsoft SQL Server admitidas por su servidor, podemos ejecutar la
siguiente consulta:
SELECT
* FROM sys.fn_helpcollations()
WHERE
name LIKE 'SQL%';
con esta
sentencia podemos observar casi 80 renglones indicando el nombre y la descripción
asociada con las intercalaciones.
Intercalación de Windows
El nombre de intercalación
de Windows se compone del designador de intercalación y los estilos de comparación,
siguiendo la siguiente sintaxis.
Nombre_Intercalacion
= DesignadorIntercalación_EstiloComparación
Donde:
- DesignadorIntercalación Especifica las reglas de intercalación base utilizadas por la intercalación de Windows. Las reglas básicas de intercalación cubren lo siguiente: Las reglas de clasificación y comparación que se aplican cuando se especifica la clasificación del diccionario. Las reglas de clasificación se basan en el alfabeto o el idioma. La página de códigos utilizada para almacenar datos de tipo alfabético.
- EstilosComparación como ya se mencionó, identifican la sensibilidad de mayúsculas y minúsculas, la sensibilidad en acentos, también en este caso se puede indicar la sensibilidad de tipos kana, se especifica KS indicando sensible a tipos kana y la omisión indica insensible a tipos kana; la sensibilidad de ancho se especifica colocando WS indicando sensible al ancho y la omisión indica insensible al ancho, obviamente este ultimo se refiere a los tipos kana. Ya se ha indicado que puede indicarse el orden de clasificación binario compatible con las versiones anteriores o la especificación de un orden de clasificación binario que use semántica de comparación de puntos de código. A partir de Microsoft SQL Server 2017, es posible indicar una opción denominada sensibilidad de variación al selector, indicando VSS se establece la variación sensible al selector y la omisión indicará la variación insensible al selector.
- Es importante indicar qué, dependiendo de la versión de la clasificación, algunos puntos de código pueden no tener pesos de clasificación y/o asignaciones en mayúsculas/minúsculas definidas. Finalmente, es posible que en algunos nombres de intercalación se especifique la existencia de caracteres suplementarios (SC), la omisión de este indica que no se contemplan caracteres suplementarios.
Para enumerar las
intercalaciones de Microsoft SQL Server admitidas por su servidor, podemos ejecutar la
siguiente consulta:
SELECT
* FROM sys.fn_helpcollations()
WHERE
name NOT LIKE 'SQL%';
Con esta
sentencia podemos observar más de 3000 renglones indicando el nombre y la descripción
asociada con las intercalaciones.
Funcionamiento
Cómo es posible
observar, la intercalación es utilizada para las columnas que almacenan
caracteres alfabéticos, entre los que se encuentran los tipos CHAR, VARCHAR y NVARCHAR.
Al momento de la instalación
de una instancia de Microsoft SQL Server se solicita se indique cual intercalación se
utilizara en esa instancia, por ello, es posible que en un servidor tengamos
instancias que utilicen intercalación diferente entre ellas.
La intercalación,
durante la actividad de instalación de una nueva instancia se presenta en la
sección de configuración del servidor, por omisión, se muestra la intercalación
denominada SQL_Latin1_General_CP1_CI_AS, lo que indica una intercalación de Microsoft SQL
Server usando las reglas de orden Latin1_General, con una pagina de código 1252
con insensibilidad a las mayúsculas y minúsculas, y sensible a los acentos, como
se aprecia en la siguiente figura.

La selección de
una intercalación diferente se logra oprimiendo el botón, identificado como
[Customize…], no abundaremos en este punto ya que no estamos tratando el tema
de la instalación.
Esta intercalación
será entonces la que mantenga en las 4 bases de datos de sistema (master,
tempdb, msdb y model). Para revisar la
intercalación que se tiene una instancia de Microsoft SQL Server, podemos revisar las
propiedades y aparece el nombre de la intercalación utilizada en la primera
página de las propiedades, como se observa en la siguiente imagen:

O bien, es
posible ejecutar la siguiente sentencia usando T-SQL
SELECT SERVERPROPERTY(‘COLLATION’) as
Intercalacion
El resultado de ésta
sentencia nos brindara cómo resultado el nombre de la intercalación que se
encuentra definida en la instancia de Microsoft SQL Server.
De esta manera,
cuando se crea una base de datos de usuario en la instancia de Microsoft SQL Server, la
base de datos a crear mantendrá la intercalación de la instancia, a menos que
se especifique en la cláusula de creación, un nombre diferente de intercalación.
Es posible revisar la intercalación que se encuentra definida para la base de
datos usando las propiedades de esta, mostrando la información en las
propiedades generales, como se muestra a continuación:
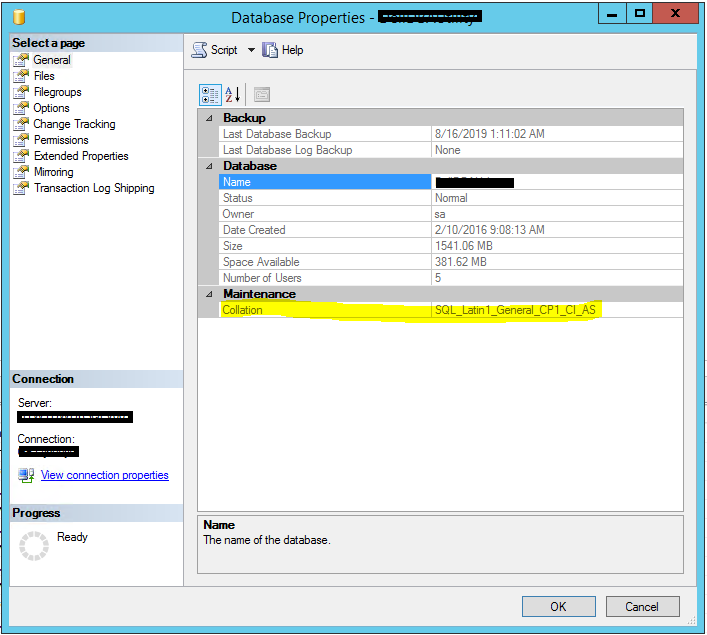
También es
posible obtener el nombre de la intercalación que esta usando una base de
datos, usando la siguiente sentencia de T-SQL:
SELECT
collation_name as Intercalacion
FROM
sys.databases
WHERE name = ‘baseDatos’
Así, cuando se
crea una tabla dentro de una base de datos de usuario, todas las columnas de
los tipos CHAR, VARCHAR, NVARCHAR tendrán la intercalación de la base de datos,
a menos que se indique un nombre diferente de intercalación diferente para esa
columna.
La intercalación
de cada columna se puede observar en las propiedades de columna, como se puede
observar en la siguiente figura:

Si se desea
conocer la intercalación de todas las columnas de datos alfabéticos de una
tabla en una determinada base de datos utilice la siguiente sentencia de T-SQL:
USE
[database]
GO
SELECT
name as Columna, TYPE_NAME(user_type_id) as DataType, collation_name as
Intercalacion
FROM
sys.columns
WHERE
object_id = OBJECT_ID(‘tableName’)
AND
collation_name IS NOT NULL;
Intercalaciones diferentes
Que pasa si la
instancia de Microsoft SQL Server esta utilizando la intercalación
SQL_Latin1_General_CP1_CI_AS (Latin1-General, case-insensitive,
accent-sensitive, kanatype-insensitive, width-insensitive for Unicode Data, Microsoft SQL
Server Sort Order 52 on Code Page 1252 for non-Unicode Data) y mi base de datos
esta utilizado SQL_Latin1_General_CP1251_CI_AS (Latin1-General,
case-insensitive, accent-sensitive, kanatype-insensitive, width-insensitive for
Unicode Data, Microsoft SQL Server Sort Order 106 on Code Page 1251 for non-Unicode
Data)? aquí la diferencia esta en el ordenamiento, en el primer caso se usa el
orden 52 y en el segundo caso el orden 106.
Hay que recordar
que al momento de llevar a cabo una consulta dentro de Microsoft SQL Server, los
resultados intermedios se llevan a cabo en la base de datos tempdb, por lo que al momento de llevar a cabo
comparaciones y ordenamiento en la consulta, tratara de usar el orden de intercalación
de la base de datos tempdb, esto es, usara la que esta definida para la
instancia de Microsoft SQL Server, y es posible que indique un mensaje de error o bien,
el resultado de la consulta sea en un orden diferente al deseado. es por ello por
lo que debe usarse la cláusula COLLATE para indicar que tipo de intercalación se
desea, ya sea para la creación de una base de datos, como para la creación de
alguna columna en una tabla, o bien, para la realización de las consultas a los
datos almacenados.
Crear una base de datos
Para crear una
base de datos usando una intercalación especifica, diferente de la que se esta
usando en la instancia actual de Microsoft SQL Server, se puede utilizar la siguiente
sentencia, para más información de la sentencia viste CREATE DATABASE.
CREATE
DATABASE Sample
ON
PRIMARY
(NAME
= Sample)
LOG
ON
(NAME
= Sample_Log)
COLLATE
SQL_Latin1_General_CP1_CS_AS;
La anterior
sentencia creara una base de datos con la intercalación de SQL con las reglas
de orden Latin1_General usando la página de código 1252 (CP1), sensible entre
mayúsculas y minúsculas (CS) y con sensibilidad en los acentos (AS).
Crear una Tabla
Se sabe que la
intercalación es una propiedad que se hereda, de una instancia de servidor a
base de datos, de base de datos a tabla, en las columnas que son alfabéticas,
es por ello que durante la creación de una tabla generalmente no se indica una
intercalación diferente, pero es posible crear una tabla dentro de una base de
datos con intercalación, diferente a la de la base de datos, en una columna,
para lo que utilizaremos una sentencia de creación como la que se indica a
continuación, para mas información de la sentencia visite CREATE TABLE.
CREATE
TABLE SampleTab1
(
Col1 int IDENTITY (1,1),
Col2 varchar(20) COLLATE
SQL_Latin1_General_CP1_CS_AS,
Col3 varchar(20)
);
Como podemos ver,
en este ejemplo, si la base de datos tiene la intercalación SQL_Latin1_General_CP1_CS_AS
que es sensible en el uso de las mayúsculas y minúsculas, en la columna Col2 se
ha indicado que se desea que se utilice una intercalación que se insensible a
las mayúsculas y minúsculas, y ¿qué significa eso? Pues significa que muestras
para la columna Col3 y todas las columnas que se definan con la intercalación
por omisión dentro de la base de datos se mantendrá el orden de presentación de
los resultados permitiendo la presentación de las mayúsculas en primer lugar y
después las minúsculas, pero en la columna Col2, no se distinguirá entre
mayúsculas y minúsculas para la presentación de los resultados.
Consultas
Hemos hecho el ejercicio
utilizando un servidor que cuenta con la intercalación SQL_Latin1_General_CP1_CI_AS,
y utilizando la definición de tabla que hemos definido anteriormente, insertamos
los siguientes valores:
INSERT INTO SampleTab1
VALUES
('Madrid',
'Madrid'),
('Morelos','MORELOS'),
('MORELOS',
'Morelos'),
('Morelos',
'Morelos'),
('Merida',
'Mérida'),
('Mérida',
'Merida'),
('MÉRIDA',
'Merida'),
('Mérida',
'MÉRIDA'),
('Michoacan',
'Michoacan'),
('Michoacán',
'MICHOACAN'),
('MICHOACÁN',
'Michoacán'),
('Mexico',
'México'),
('México',
'Mexico'),
('MEXICO',
'México'),
('MÉXICO',
'MEXICO');
Realizando una
consulta usando la intercalación de la base de datos
SELECT
Col1, Col2, Col3
FROM
SampleTab1
ORDER
BY Col2 COLLATE database_default;
En este caso el
resultado de la consulta fue el siguiente:
Col1
|
Col2
|
Col3
|
1
|
Madrid
|
Madrid
|
5
|
Merida
|
Mérida
|
6
|
Mérida
|
Merida
|
7
|
MÉRIDA
|
Merida
|
8
|
Mérida
|
MÉRIDA
|
12
|
Mexico
|
México
|
14
|
MEXICO
|
México
|
15
|
MÉXICO
|
MEXICO
|
13
|
México
|
Mexico
|
9
|
Michoacan
|
Michoacan
|
10
|
Michoacán
|
MICHOACAN
|
11
|
MICHOACÁN
|
Michoacán
|
2
|
Morelos
|
MORELOS
|
3
|
MORELOS
|
Morelos
|
4
|
Morelos
|
Morelos
|
Realizando una
consulta usando la intercalación de la columna
SELECT
Col1, Col2, Col3
FROM
SampleTab1
ORDER
BY Col2 COLLATE SQL_Latin1_General_CP1_CS_AS;
Para esta
consulta, el resultado es:
Col1
|
Col2
|
Col3
|
1
|
Madrid
|
Madrid
|
5
|
Merida
|
Mérida
|
7
|
MÉRIDA
|
Merida
|
8
|
Mérida
|
MÉRIDA
|
6
|
Mérida
|
Merida
|
14
|
MEXICO
|
México
|
12
|
Mexico
|
México
|
15
|
MÉXICO
|
MEXICO
|
13
|
México
|
Mexico
|
11
|
MICHOACÁN
|
Michoacán
|
9
|
Michoacan
|
Michoacan
|
10
|
Michoacán
|
MICHOACAN
|
3
|
MORELOS
|
Morelos
|
4
|
Morelos
|
Morelos
|
2
|
Morelos
|
MORELOS
|
Realizando una
consulta usando la intercalación de la instancia
SELECT
Col1, Col2, Col3
FROM
SampleTab1
ORDER BY Col3;
En este caso, el
resultado de la consulta es:
Col1
|
Col2
|
Col3
|
1
|
Madrid
|
Madrid
|
6
|
Mérida
|
Merida
|
7
|
MÉRIDA
|
Merida
|
8
|
Mérida
|
MÉRIDA
|
5
|
Merida
|
Mérida
|
13
|
México
|
Mexico
|
15
|
MÉXICO
|
MEXICO
|
14
|
MEXICO
|
México
|
12
|
Mexico
|
México
|
9
|
Michoacan
|
Michoacan
|
10
|
Michoacán
|
MICHOACAN
|
11
|
MICHOACÁN
|
Michoacán
|
2
|
Morelos
|
MORELOS
|
3
|
MORELOS
|
Morelos
|
4
|
Morelos
|
Morelos
|
Comentarios
Como hemos visto,
la intercalación se ha usado en los sistemas de computo en general desde hace
mucho tiempo, y tiene gran relevancia en los sistemas de administración de
bases de datos, como Microsoft SQL Server, debido a que debe llevarse a cabo el cotejo de
elementos para efectuar las ordenaciones de la información que se debe entregar
al realizar la consulta de los datos almacenados. Es importante recordar que
dependiendo de las características de la intercalación que se utilice para realizar
las consultas, es la forma en que se nos presentará la información.
Recordemos que la
intercalación, además de tomar en cuenta el conjunto de caracteres que se
utilizan, también toma en cuenta la sensibilidad de las mayúsculas y minúsculas
y la importancia de los acentos, recordando que, en caso de la
sensibilidad en mayúsculas y minúsculas, primero se colocan las mayúsculas y después
las minúsculas y que, en caso de las palabras acentuadas, las letras acentuadas
van después de las minúsculas sin acentuar. Como hemos observado en los
resultados obtenidos de los ejercicios.
No hay comentarios.:
Publicar un comentario